About

Data Scientist & Operations Research Engineer
I’m a Data Science & Operations Research engineer with a degree from INSEA, passionate about transforming complex data into actionable insights and designing solutions that work in the real world.
My work spans machine learning, optimization, and automation—from OCR-based document processing pipelines to RAG-powered chatbots and multi-agent reinforcement learning systems. I apply software engineering best practices including CI/CD, testing, and clean code principles to all my projects.
Contact
- Email: boulaich.mohamed970@gmail.com
- LinkedIn: Mohamed Boulaich
- GitHub: BlcMed
Education
PhD, Combinatorial Optimization
École de technologie supérieure (ÉTS) | Montreal, Canada | Starting Jan 2026
Engineering, Data Science
The National Institute of Statistics and Applied Economics (INSEA) | Rabat, Morocco | 2022 - 2025
SPE, MP*
Higher School Preparatory Classes (CPGE) Moulay Idriss | Fes, Morocco | 2021 - 2022
Professional Experience
AI Research Intern (PFE) – Multi-Agent Reinforcement Learning
Ai Movement, UM6P | Rabat, Morocco | Feb 2025 - Aug 2025
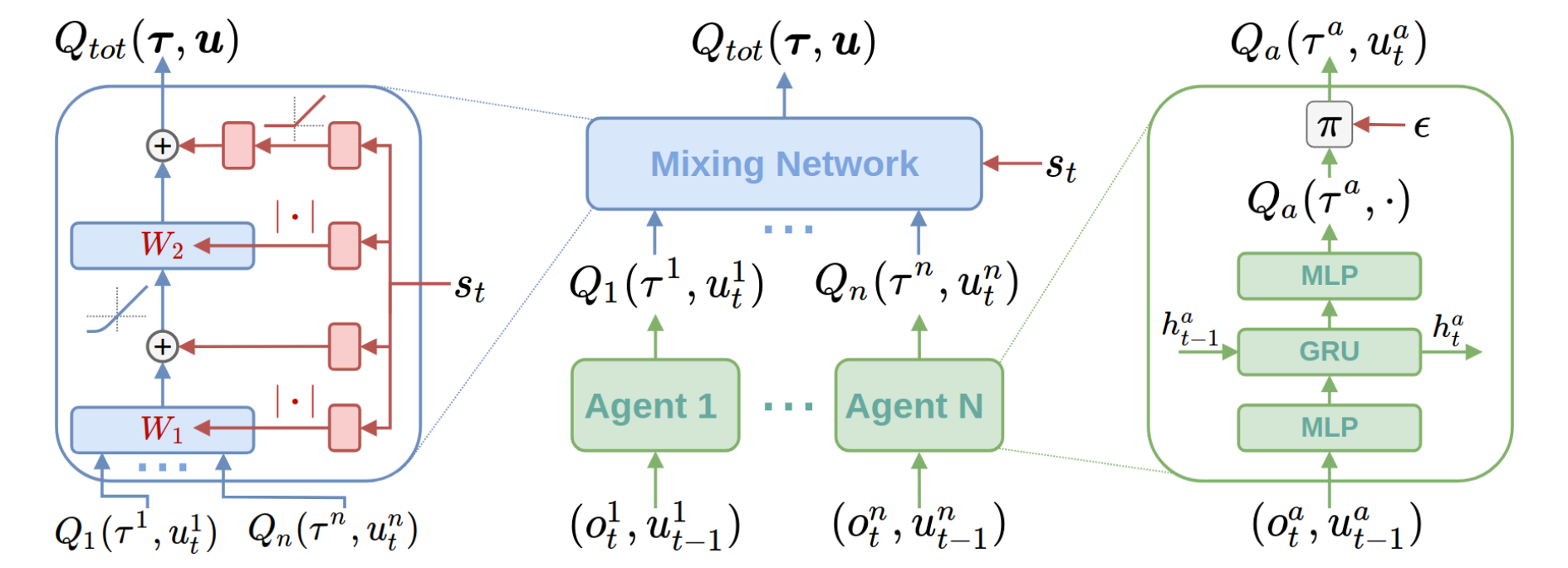
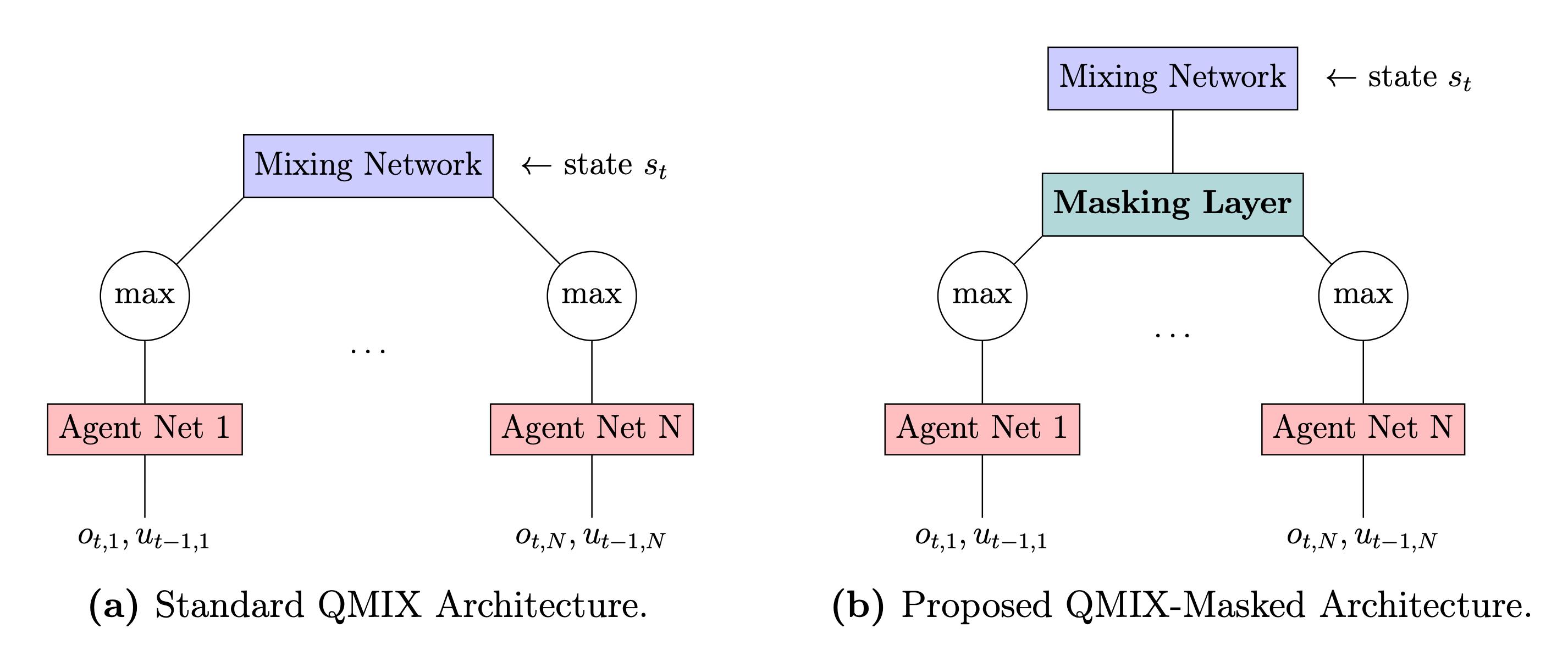
- Designed novel QMIX variant leveraging agent contribution masking and regularization
- Achieved compressed model with lower computational overhead for cooperative multi-agent tasks
- Conducted state-of-the-art review of MARL algorithms and benchmarked using PettingZoo and PyMarl
Machine Learning Freelancer - OCR for Tables
Independent Consultant | Remote | Jul 2024 - Oct 2024
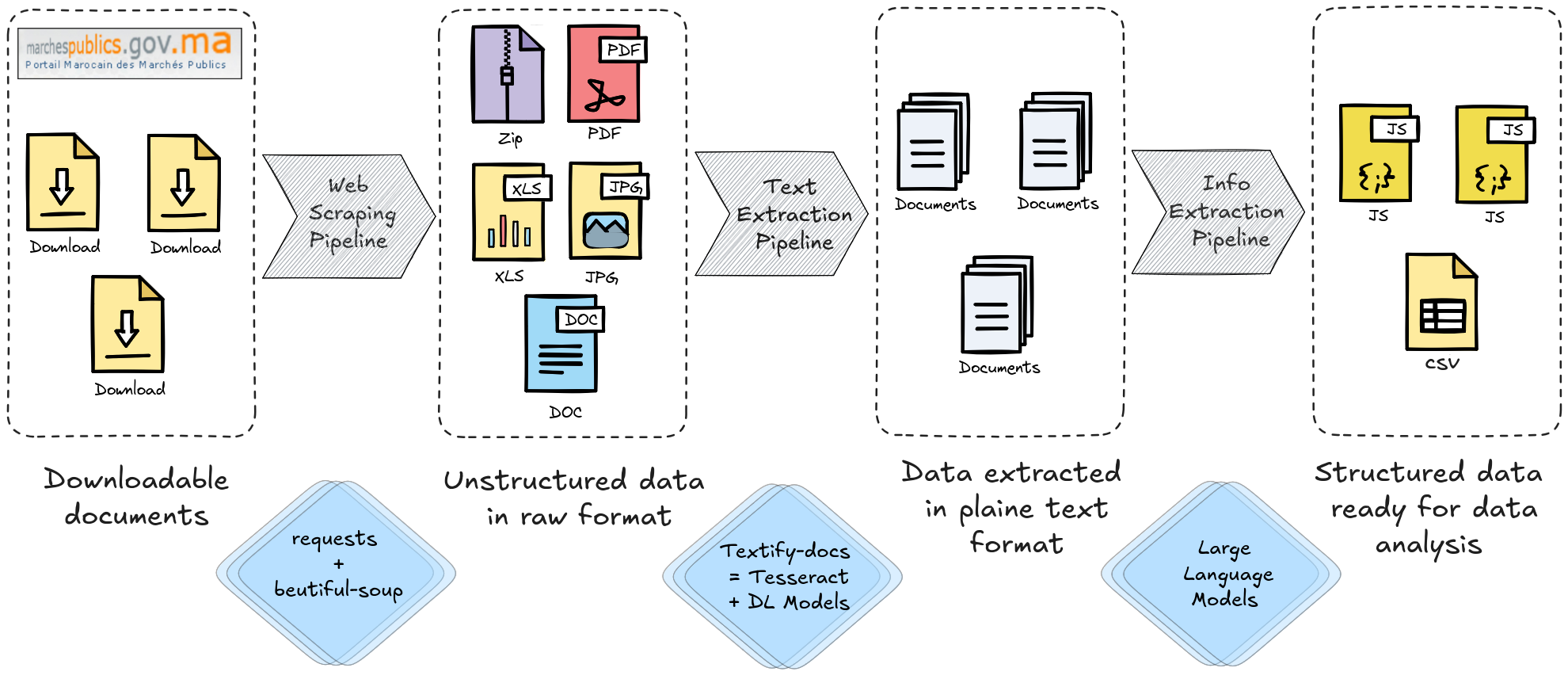
- Developed textify-docs, a Python library for text extraction from diverse document formats
- Built preprocessing pipeline using OpenCV and Pytesseract for efficient text extraction
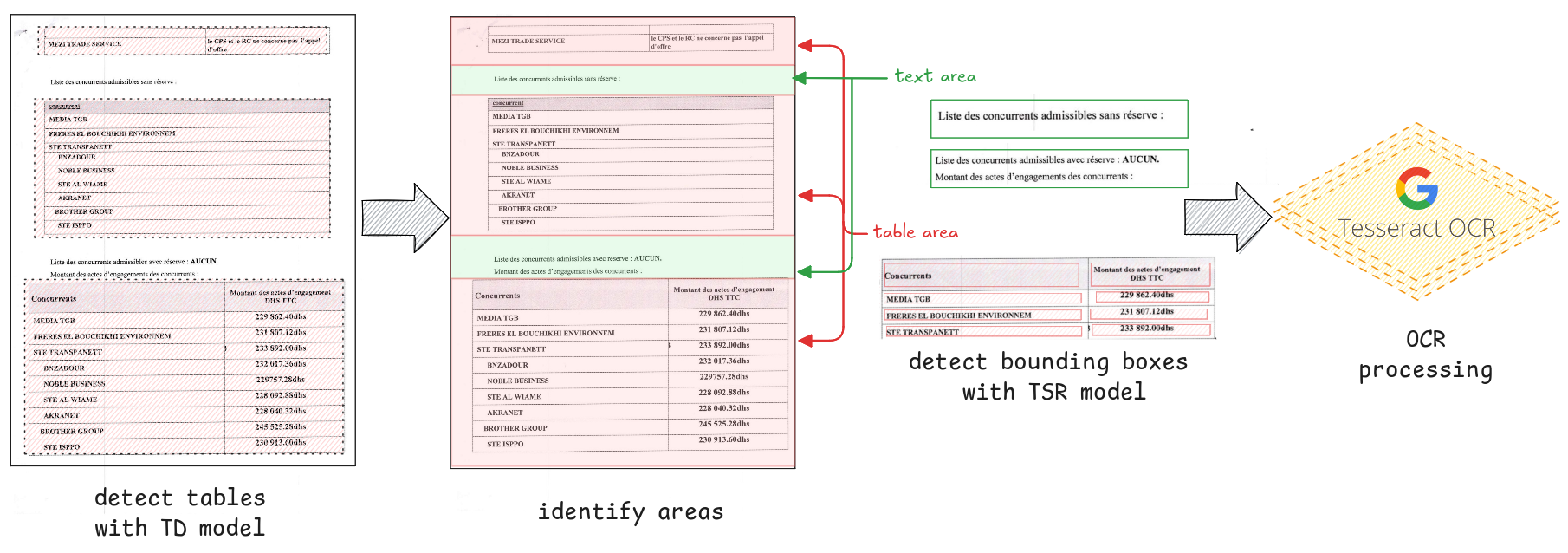
- Applied Table Transformer (TATR) based on DETR to enhance table extraction accuracy
- Utilized LLMs to identify and structure relevant information
AI Engineering Intern - RAG
Maroc Telecom | Rabat, Morocco | Jun 2024 - Aug 2024
- Leveraged LlamaIndex framework with vector indexing for efficient information retrieval
- Integrated ChromaDB for optimized storage and loading of embeddings
- Optimized chatbot responses through prompt engineering and hyperparameter tuning
- Created user-friendly Streamlit interface

Data Analyst Intern
Higher Planning Commission (HCP) | Tangier, Morocco | Jun 2023 - Jul 2023
- Cleaned and preprocessed demographic data, applied linear regression for 2024 population forecasting
- Created interactive maps using Folium for visualizing population distributions
Skills
Languages: English (TOEFL 82), French (fluent), Arabic (native)
Statistics: Statistical Inference, Machine Learning Methodology, Traditional Modeling, GLM, Time Series Analysis, HMM, Stochastic Processes, Queuing Theory
Operations Research: Linear/Integer Programming, Stochastic Optimization, Decomposition Methods (Dantzig-Wolfe, Benders, Column Generation), Metaheuristics (SA, GA, TS), Graph Theory
Libraries: NumPy, Pandas, Scikit-Learn, PyTorch, Transformers, SpaCy, Seaborn
DevOps/MLOps: Git, CI/CD (GitHub Actions), Testing (tox, pytest), Docker, Code Quality Tools, Agile/Scrum
Data Tools: Apache Airflow, Apache Superset